Pretraining, more interesting than I thought
Started watching Andrej Karpathy's video: Deep Dive into LLMs like ChatGPT
Below are my current notes.
Pretraining data:
The pretraining step in LLMs development is the process of downloading and preprocessing data from all over the Internet. This process can be summarized in the image below that I got from the :
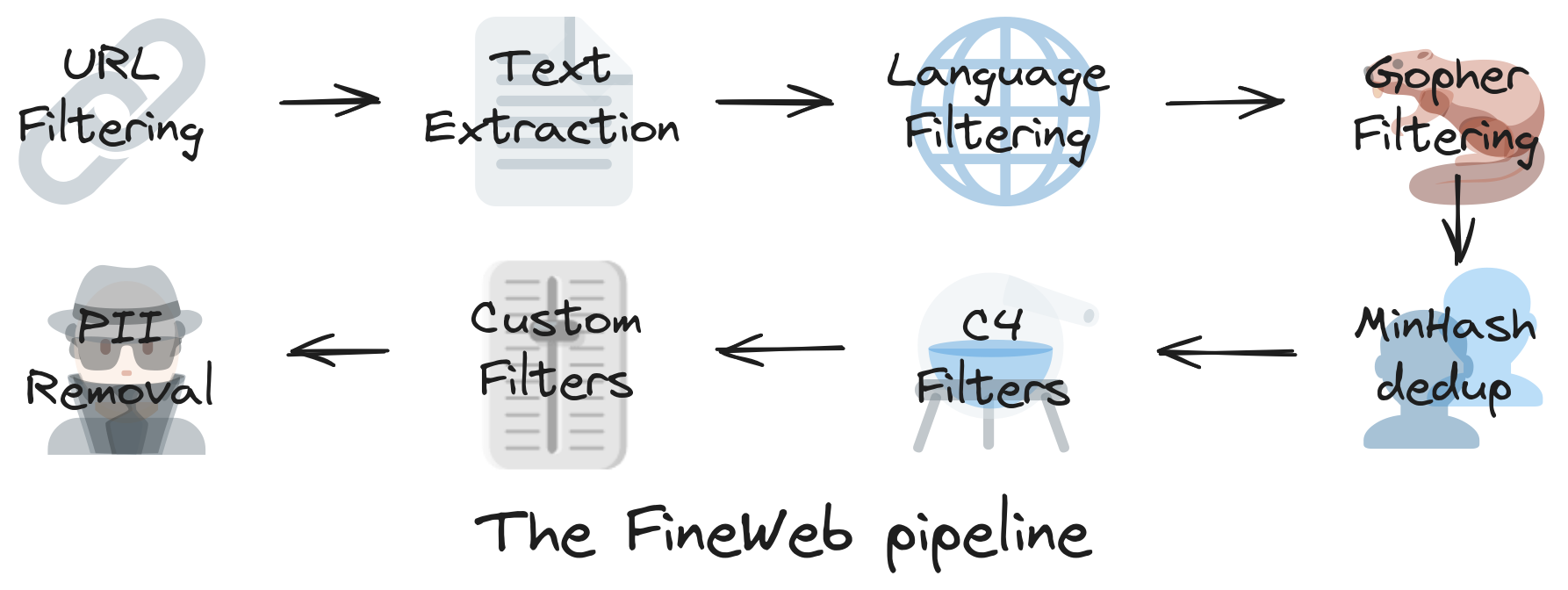
A typical source of this data is CommonCrawl. However this data contains a bunch of undesirable data from many URLs that we don't want to include in the dataset, like adult sites, so this data needs to be filtered.
1 . URL filtering
To filter this data there's a BlackList of URLs organized by category and intent of each URL. This list has been maintained many years and it's a good source for this data.
2. Language Filtering:
There is a language filter that is applied to the data to get data in a preferred language, most of the times English is the preferred language for many datasets, like Fineweb dataset.
There are more steps to filter this data but Andrej Only described these 2 in detail so I'll leave those for later consultation.
This is an example of how text ends up being stored in the dataset:
How AP reported in all formats from tornado-stricken regionsMarch 8, 2012 When the first serious bout of tornadoes of 2012 blew through middle America in the middle of the night, they touched down in places hours from any AP bureau. Our closest video journalist was Chicago-based Robert Ray, who dropped his plans to travel to Georgia for Super Tuesday, booked several flights to the cities closest to the strikes and headed for the airport. He’d decide once there which flight to take. He never got on board a plane. Instead, he ended up driving toward Harrisburg, Ill., where initial reports suggested a town was destroyed. That decision turned out to be a lucky break for the AP. Twice. Ray was among the first journalists to arrive and he confirmed those reports -- in all formats. He shot powerful video, put victims on the phone with AP Radio and played back sound to an editor who transcribed the interviews and put the material on text wires. He then walked around the devastation with the Central Regional Desk on the line, talking to victims with the phone held so close that editors could transcribe his interviews in real time.
Andrej's Karpathy videos are AWESOME. I am so happy that he's doing this educational work. Also, I didn't know that the fine web dataset existed, this is great I might be able to use it in my job or for personal projects. Next section of Andrej's video is tokenization, I feel very excited about that part, it's like diving deeper into the matrix to see how things work.
Previously I saw LLMs as something so obscure that didn't have any hope that this was going to be easy or even possible to grasp this quick, but Andrej's work on sharing this info gives me hope that I can be as good as these top engineers that work at these companies.
I am not sure I would like to work at a place like OpenAI, I don't like Sam Altman. I would prefer to work on personal projects using this knowledge, or useless things that are just fun. That would make me truly happy.
(˶ᵔ ᵕ ᵔ˶)